Summary:
AI Text Classifier
The goal of this project was to create a machine learning model that could identify "toxic" comments. Our idea was to create a tool that would be able to filter content on social media or other platforms without the need of blacklisting specific words or phrases.
This was achieved using a naive Bayes probability model which assumes each variable is conditionally independent. This is rarely true, but greatly simplifies the calculations required and often gives accurate results for text classification.
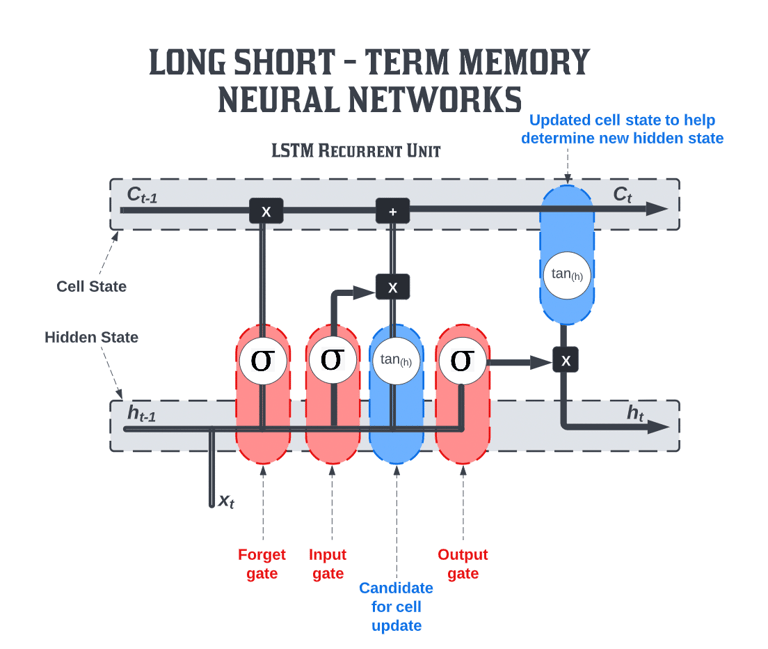
The machine learning model used for this project is a long short-term memory (LSTM) Recurrent Neural Network (RNN). This type of model is quite effective for analyzing natural speech, as it tends to be able to learn how to contextualize phrases. This helps to differentiate content that contains words which would only be considered "toxic" within a specific context (slang terms with dual meanings are a good example of this).
Text is cleaned before being processed by the neural network. This is done by removing punctuation and special characters, and converting everything to lowercase This helps to remove noise in the data, resulting in a more accurate model.
The text is also tokenized, which converts it into a machine-readable numerical format.
Technical Explanation: